Why Propose VLA-RFT?
Background. Vision-Language-Action (VLA) models typically rely on imitation learning for training,
which performs well in static environments. However, they perform poorly when faced with real-world changes,
as slight deviations can cause Policy to gradually deviate from the expert demonstration,
leading to error accumulation and affecting robustness.
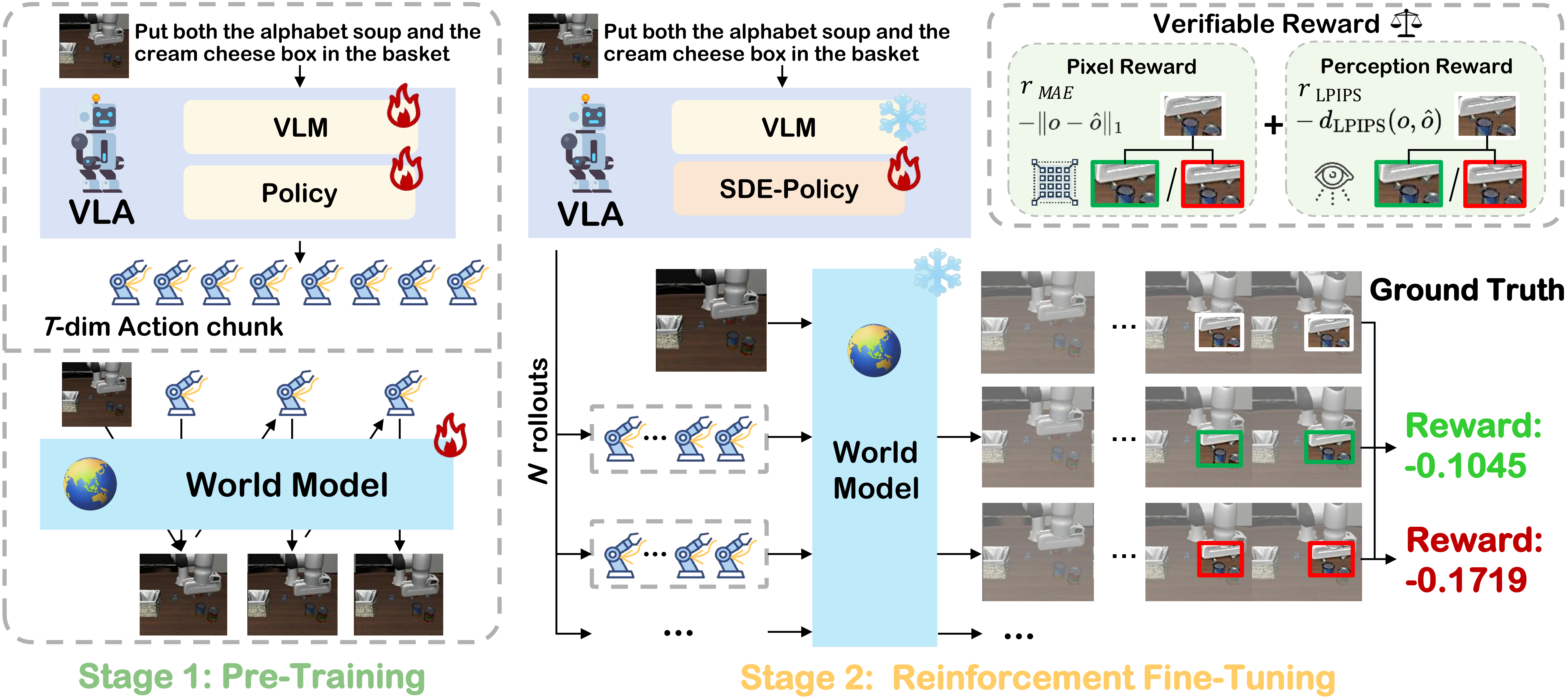
In this work. We introduce VLA-RFT, a reinforcement fine-tuning framework that
leverages a data-driven world model as a controllable simulator. Trained from real
interaction data, the simulator predicts future visual observations conditioned on
actions, allowing policy rollouts with dense, trajectory-level rewards derived from
goal-achieving references. This design delivers an efficient and action-aligned
learning signal, lowering sample requirements.
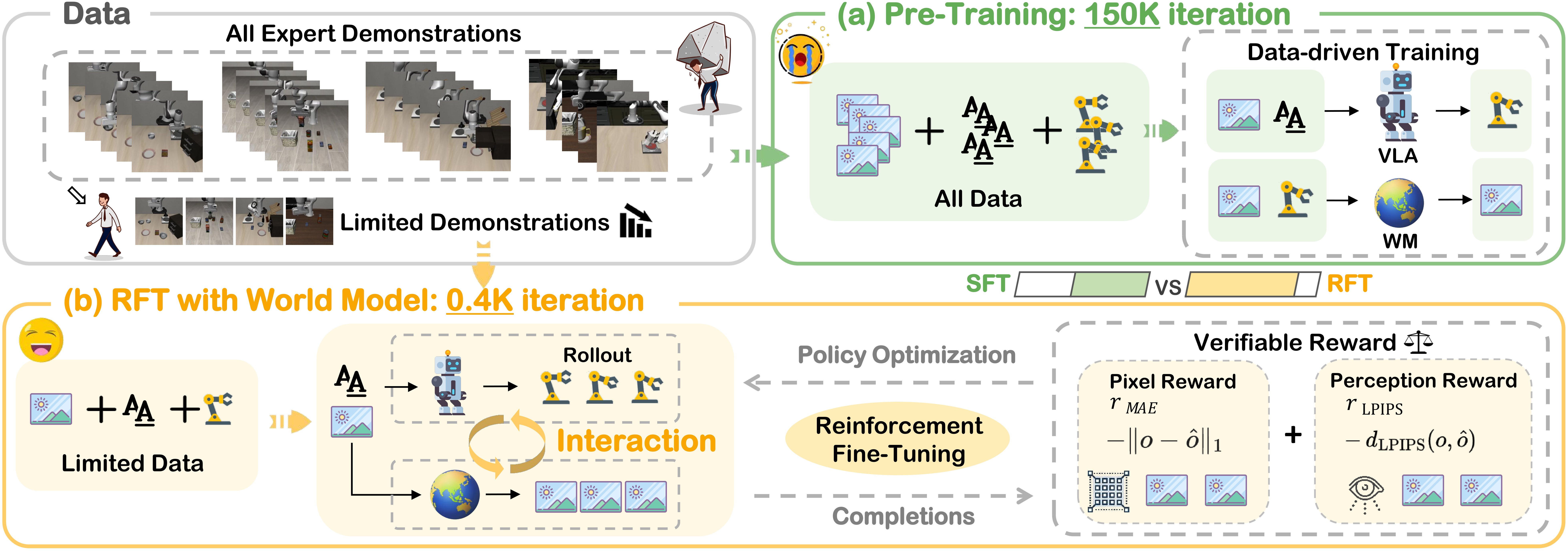
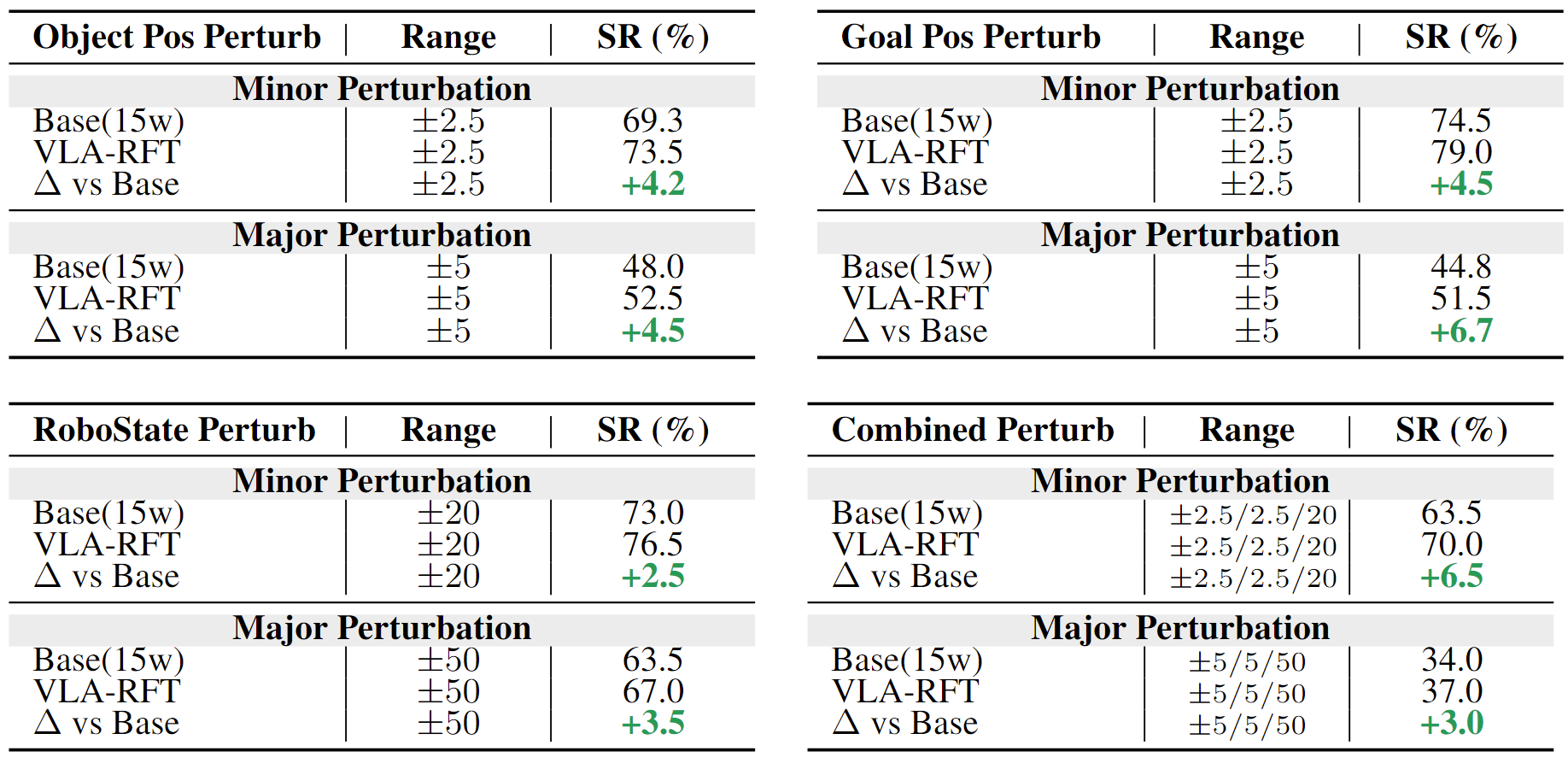
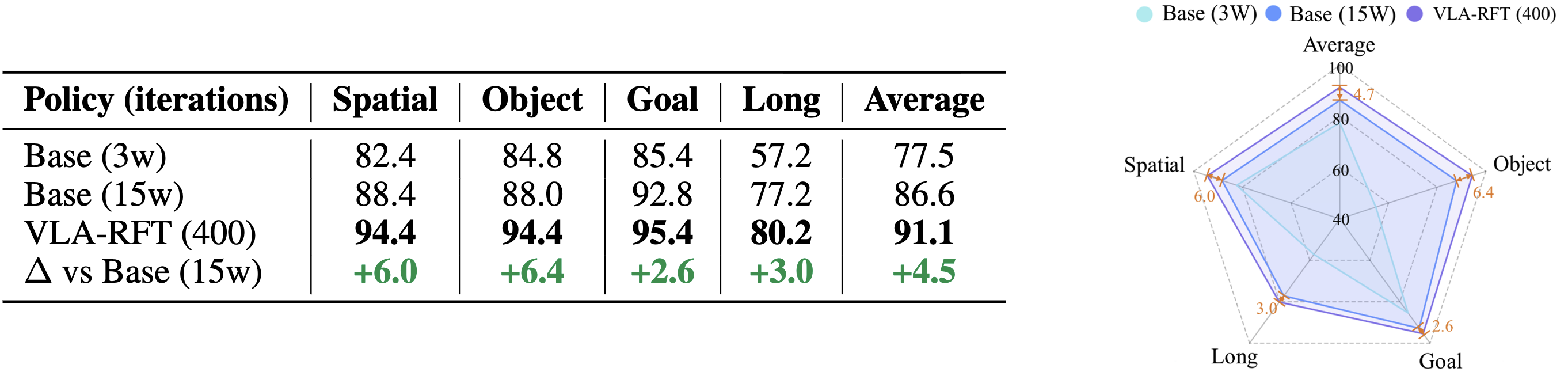
Performance. With fewer than 400 fine-tuning steps, VLA-RFT surpasses strong supervised baselines and achieves greater efficiency than simulator-based RL.

VLA-Adapter model with the state-of-the-art performance.